By Wesley Monteith-Finas and Przemyslaw Kuznicki
Introduction
In recent years, the advent of large language models (LLMs) has sparked tremendous excitement across industries. From generating human-like text to translating languages and answering complex questions, these models have captivated the imagination of professionals and researchers alike. Among the most notable breakthroughs is OpenAI’s GPT series1, which has set a new standard in natural language processing (NLP) and transformed how we interact with AI systems.
This whitepaper demonstrates how, within the span of two months, Marbls was able to develop an AI-powered solution to automate answering cybersecurity surveys. To attain this goal, we explored key strategies that enhance the performance of LLMs, including prompt engineering, in-context learning (ICL), embedding models, retrieval-augmented generation2 (RAG), and fine-tuning.
Table 1: Terminology Used
| Natural Language Processing (NLP) | A field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language. |
| Large Language Model (LLM) | A type of artificial intelligence that can understand and generate human language. It learns patterns from vast amounts of text data (books, websites, articles, …) and uses that knowledge to predict the next word or phrase in a sequence of text. |
| Prompting | Refers to providing an input, typically in the form of a question, statement, or command, to a large language model to elicit a specific response. The input, known as a “prompt”, serves as a starting point for the model to generate a relevant output. By carefully crafting prompts, one can guide the model to perform a wide range of tasks. Prompting is the method by which interaction with the model is initiated and directed. |
| Embedding Models | A type of machine learning model that transforms text into numerical representations called “embeddings.” These embeddings capture the meaning and relationships between different words or phrases by placing them in a mathematical space where similar concepts are closer together, and dissimilar ones are further apart. |
| Cosine Similarity | A similarity measure, indicating how similar two pieces of text are by comparing the angle between them when represented as vectors. |
| In-Context Learning (ICL) | In-context learning is a paradigm that allows language models to learn tasks given only a few examples in the form of demonstration.3 It is like teaching someone a language rule by showing them just a few example sentences within a prompt, without retraining their knowledge from scratch. |
| Retrieval Augmented Generation (RAG) | A technique used in AI systems to provide more accurate and useful answers by looking up facts first, then using those facts to create a smarter, more informed response. This is done in two steps: Retrieval: The model first searches through a large database or set of documents to find relevant information. Generation: It then uses that information to create a response, ensuring that the answer is more specific and up to date than what the model might generate from its training alone. |
| Reranking Model | A reranking model in a RAG system is used to reorder the retrieved documents or passages based on their relevance to the query. |
| Fine Tuning (FT) | The process of taking a pre-trained large language model and further training it on a smaller, more specific dataset to improve its performance on a particular task. While the original model has been trained on vast amounts of general text, fine-tuning allows it to specialize by adjusting its internal settings based on the new, focused data. |
| Overfitting | Overfitting occurs when a machine learning model becomes too closely tailored to the training data, learning its details and noise rather than general patterns. |
| Hallucinations | Instances when a model generates information that is inaccurate and non-factual. Hallucinations occur because the model may predict text based on patterns in its training data rather than facts, leading to misleading or false outputs. This is a key challenge when using AI for tasks that require precise, fact-based responses. |
Problem Statement
As part of the business development activities, Marbls participates in various cybersecurity surveys which are a key part of the sales cycle. Clients often inquire how Marbls addresses specific cybersecurity threats through questions or statements that require responses of “Yes”, “No”, or “Not Applicable”, along with short, straightforward, justifications. Automating this process is crucial for efficiency and accuracy.
During the last several years on the market, Marbls has participated in multiple cyber security surveys. As a result, it has answered and collected around one thousand questions, of which four hundred were justified diligently. Utilizing this data, the goal is to fully or partially automate the processing of future cybersecurity surveys with an AI system.
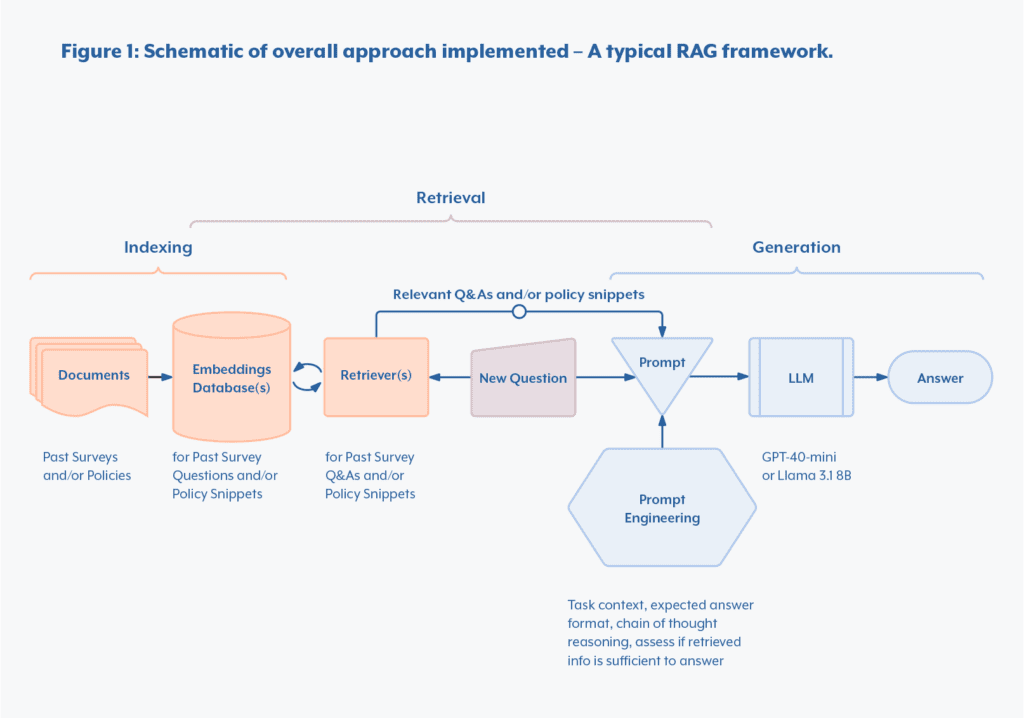
Bridging the Knowledge Gap: Overcoming LLM Unawareness
A. Evaluation Strategy
To assess the performance of our AI systems we rated the machine generated responses by hand. We looked at the quality of the responses on a set of held out questions, unused for implementing the AI system itself, and hand labelled each generated answer in three arbitrary categories: high-, medium- and low-quality answers based on the accuracy, clarity and the conciseness of the answer.
B. Baseline
LLMs like OpenAI’s GPT-4o-mini are not experts in how Marbls handles cybersecurity regulations. If asked a cybersecurity question, the output answer would likely be marked as low-quality. For example:

The response is unspecific to Marbls, too long and doesn’t respect a specific output format.
Below we will show how to add context, including task contextualization, in-context learning, RAG using embedding models, and fine-tuning.
C. Contextualization
As demonstrated above, the response quality is poor because the model lacks specific information on how Marbls handles “security incidents.”
Therefore, to make LLMs more informed, you use them as is, but you change the way you interact with them, via prompt engineering. Indeed, as seen in the example above, they have strong understanding, reasoning and writing capabilities.4
Firstly, start the prompt by giving some context as to what job the LLM is expected to do. In our case we tell the model that it is “a consultant working for Marbls LLC, filling a cyber security related survey for a potential future client.”
Secondly, specify the desired output: “Please answer the given question in the following template: ##Reason: {reason} ##Answer: {answer}.” Moreover, specify what you expect: “{reason} is a very detailed justification and {answer} must be either “Yes” or “Not Applicable” or “No””. By doing so, it becomes simpler to parse the model’s output for further processing, such as creating a table. This prompt is inspired by Zhang et al.’s work.5
The LLM is specifically asked to justify its answer beforehand to encourage it to think more carefully. Research has shown that LLMs tend to perform better when they think through the problem before providing a final answer. This is referred to as chain of thought reasoning.6
From now on every time you ask the LLM a question, add the task contextualization prior to it.
D. In-Context Learning
Once you’ve set up the task and told the LLM what kind of answer you expect, you need to give it enough information to make it knowledgeable about Marbls’ cybersecurity practices.
To do this, include past question-and-answer (Q&A) examples in the prompt. This helps if the new question is similar to an old one, as the LLM can use the previous answers as a guide. These examples are called “in-context examples” and should be formatted just like your initial instructions. They provide useful information and remind the LLM of the type of response you’re looking for.
You’ll also need to decide how many examples to include in the prompt. The selection of examples is handled by the retrieval part of RAG, which is covered in the next section. However, the exact number of examples you use is up to you.
E. The Art of Retrieval: Embedding Models
To improve text generation, selecting examples that offer relevant information is crucial for better answers. But how do we measure which past questions are most similar to a new question? This is where the concept of embeddings comes in, with the use of embedding models. Think of an embedding as a way to translate text into a series of numbers that represent its meaning—similar to creating a unique fingerprint for each piece of text. This allows a system to measure how closely two texts relate.
Your AI system first embeds past questions into a database. When a new question is asked it compares its embedding to your embeddings database. Using a similarity score (e.g. cosine similarity) it selects the four most relevant examples, which are included in the LLM’s prompt to generate an answer. Since embeddings capture the meaning of words, similar questions often share related terms or phrasing. For instance, questions about “password management” may provide relevant context for similar topics.
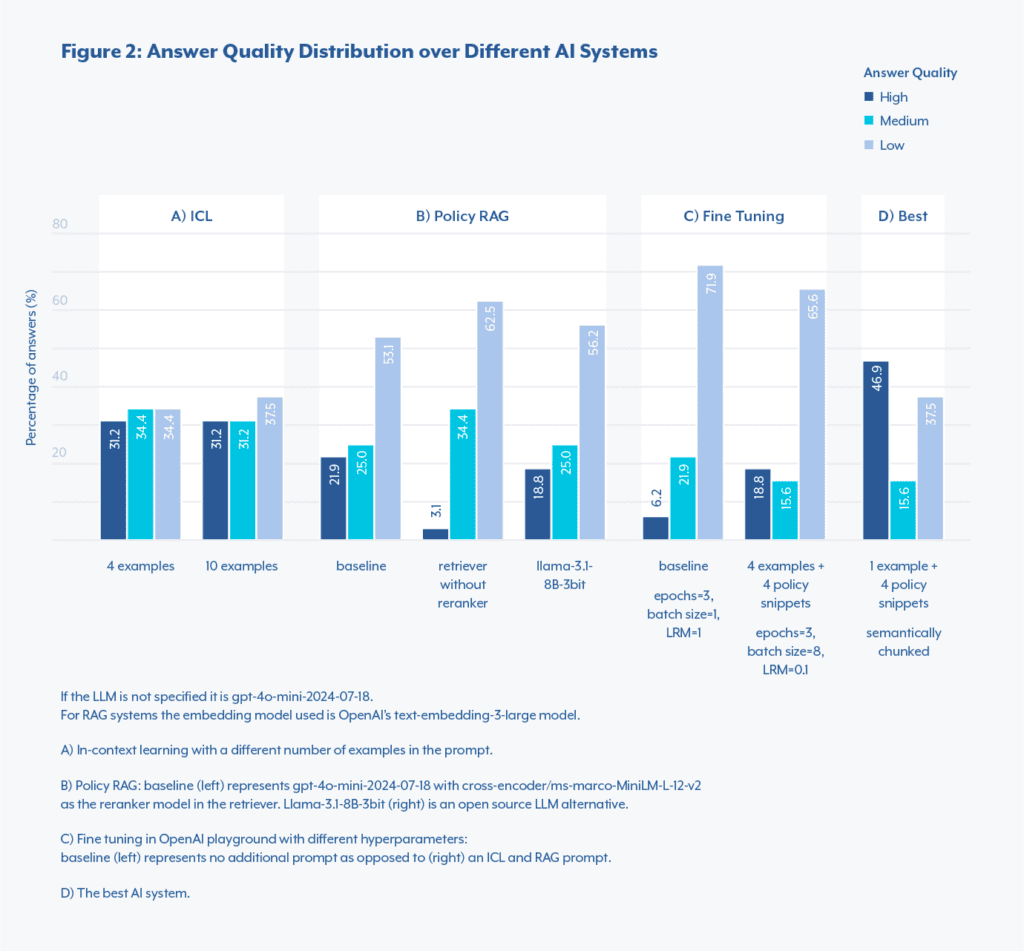
Choosing four examples is somewhat arbitrary. Including more examples might provide extra context but increases the processing time, cost, and the risk of adding irrelevant information. In our case (See Figure 2.A), the percentage of high-quality answers (31.2%) didn’t improve when using ten examples versus four.
F. Enriching Responses with Policy Documents
Companies, and Marbls is not an exception, have a wealth of information in various documents. Hence it seems natural to use them as a basis for making our AI systems more knowledgeable. In our case, two relevant cybersecurity documents –Marbls’ Acceptable Use of IT Policy and a draft of the Information Security Policy– can be utilized by the AI system.
These documents are processed similarly to past surveys. First, the text is split into chunks, which can be done in two ways: recursive character splitting and semantic chunking. Recursive character splitting breaks the document into fixed-size chunks without considering meaning, which ensures uniform chunk size but can split sentences awkwardly. In contrast, semantic chunking splits the text based on its natural structure, like sentences or paragraphs, preserving coherence and making the chunks more meaningful for retrieval.
Once split, each chunk is embedded to create a vector database of policy snippets. When a new question is asked, the AI system compares the question’s embedding with the policy snippets’ embeddings, using cosine similarity. The four most relevant snippets are added to the prompt to help the AI generate a well-informed response. Adding a reranking model, which acts as a second-pass filter on the retrieved pieces of text, can further improve performance. As shown in Figure 2.B, using a re-ranker increased the percentage of high-quality answers from 3.1% to 21.9%.
Implementing a RAG system is highly beneficial, mainly because maintaining an embedding database is cost-effective. This allows you to easily update the AI with new or revised documents, keeping the system up to date.
A helpful prompt strategy is to instruct the AI to say “I don’t know” when it lacks enough information, reducing the chances of hallucinated answers. This approach leverages the LLM’s reasoning to assess if the retrieved data is sufficient.
G. The Fine-Tuning Letdown: Why It Falls Short
Fine-tuning both an open- and a closed-source LLM is possible using the QLoRA method7 and OpenAI’s playground respectively. These systems were tested and ruled out due to their poor performance (OpenAI playground results in Figure 2.C), most probably due to the low-data regime. Fine-tuning often involves many hyperparameters (learning rate, epochs, batch size, etc…), and with limited training data, the risk of overfitting and hallucinating increases.
Open vs. Closed-Source LLMs: A Trade-off
Choosing between open-source and closed-source LLMs depends on the use case. Closed-source models, like OpenAI’s GPTs, usually perform better but are costly and less transparent, relying on APIs. Open-source models, like Meta’s Llama 3.1, offer more flexibility and control but require significant computing power.
A. Performance
In our tests, both open- and closed-source LLMs produced similar quality responses as seen in Figure 2.C (18.8% and 21.9% of high-quality answers, respectively).
B. Hardware Challenge with Open-Source LLMs
Running large models like Llama 3.1, which can have up to 405 billion parameters, demands powerful GPUs, making them difficult for organizations without high-end hardware.
C. Quantization
To reduce hardware demands, quantization reduces the bits per parameter, shrinking model size and making open-source LLMs more accessible to users with limited hardware.
D. Balancing Cost and Infrastructure
In this case study, OpenAI’s GPT-4o-mini was chosen for its easy API access, reducing the need for expensive hardware. While using a quantized Llama 3.1 would have saved API costs, it would have required costly GPU infrastructure.
Ultimately, OpenAI’s API with a low-cost server was the most efficient choice for our needs.
Results
In this case study, the best AI system was a RAG system utilizing the policy documents, where the embeddings database was created using the semantic chunking strategy. Additionally, adding the most similar example in the prompt improves performance, making it a hybrid approach between ICL and RAG. The system yielded 46.88% of high-, 15.62% of medium- and 37.5% of low- quality answers.
We also noticed that the AI system was struggling on questions requiring to refer to the norms of Marbls’ internal tools such as MS Office and Salesforce. Therefore, in addition to the previously mentioned prompt strategy additional information was added:
“Marbls uses third party vendors such as Microsoft Office, Apple and Salesforce which already meet industry standards such as ISO/IEC 27001 and NIST. […] When answering, you may rely on the security capabilities and default settings of these third-party vendors if the internal policy does not explicitly mention the control.”
If we come back to the first question asked:

In evaluating the 37.5% of low-quality responses from the AI system, it is important to note that not all these responses are hallucinations – i.e., complete fabrications or non-factual statements. Instead, there are instances where the LLM recognizes gaps in the information or the inability to retrieve relevant details from available documents. In such cases, the model might signal uncertainty or its inability to provide an accurate answer. This approach can be beneficial as it can prevent the propagation of highly inaccurate or irrelevant answers, allowing the user to avoid the time-consuming task of correcting such outputs later.
Conclusion
By integrating LLMs with retrieval-augmented generation (RAG) techniques, we successfully automated and sped up the process of responding to cybersecurity surveys at Marbls by 50%. This approach leveraged embedding models, policy documents, and past examples to enhance LLM performance without needing extensive fine-tuning.Ultimately, the solution provided a scalable, efficient, and accurate method for answering client inquiries while adhering to Marbls’ cybersecurity norms.
These implementations can be valuable to clients across various industries. For example, in legal services, this approach could automate the review of legal documents or provide instant answers to compliance questions. In customer support, embedding product manuals and FAQs could streamline technical support queries. Similarly, HR departments could benefit from automating responses to policy-related inquiries by retrieving and generating answers based on company handbooks.
By tailoring the LLM and RAG approach to specific client needs, businesses can greatly enhance their efficiency, improve response accuracy, and reduce manual workloads across various sectors.
Bibliography
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. “Language Models Are Few-Shot Learners.” arXiv, July 22, 2020. https://doi.org/10.48550/arXiv.2005.14165.
Dettmers, Tim, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. “QLoRA: Efficient Finetuning of Quantized LLMs.” arXiv, May 23, 2023. https://doi.org/10.48550/arXiv.2305.14314.
Dong, Qingxiu, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, et al. “A Survey on In-Context Learning.” arXiv, October 5, 2024. https://doi.org/10.48550/arXiv.2301.00234.
Dubey, Abhimanyu, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, et al. “The Llama 3 Herd of Models.” arXiv, August 15, 2024. https://doi.org/10.48550/arXiv.2407.21783.
Glass, Michael, Gaetano Rossiello, Md Faisal Mahbub Chowdhury, Ankita Rajaram Naik, Pengshan Cai, and Alfio Gliozzo. “Re2G: Retrieve, Rerank, Generate.” arXiv, July 13, 2022. https://doi.org/10.48550/arXiv.2207.06300.
Lewis, Patrick, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” arXiv, April 12, 2021. https://doi.org/10.48550/arXiv.2005.11401.
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al. “GPT-4 Technical Report.” arXiv, March 4, 2024. https://doi.org/10.48550/arXiv.2303.08774.
Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” arXiv, January 10, 2023. https://doi.org/10.48550/arXiv.2201.11903.
Zhang, Tianjun, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E. Gonzalez. “RAFT: Adapting Language Model to Domain Specific RAG.” arXiv, June 5, 2024. https://doi.org/10.48550/arXiv.2403.10131.
Endnotes
- Brown et al., “Language Models Are Few-Shot Learners.” ↩︎
- Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” ↩︎
- Dong et al., “A Survey on In-Context Learning.” ↩︎
- OpenAI et al.; Dubey et al., “The Llama 3 Herd of Models.” ↩︎
- Zhang et al., “RAFT.” ↩︎
- Wei et al., “Chain-of-Thought Prompting Elicits Reasoning
in Large Language Models.” ↩︎ - Dettmers et al., “QLoRA.” ↩︎